Contrastive Learning of Visual Representations
Contrastive learning has emerged as a leading paradigm for self-supervised learning of high quality visual representations from unlabeled data. It is a manifestation of a broader trend in the deep learning community in recent years that seeks to reduce the need for large amounts of labeled data through unsupervised or self-supervised pretraining. In contrastive learning, the network is trained by a contrastive loss function that discriminates between “positive” and “negative” views of images. This post would briefly introduce the contrastive framework along with some of the established baselines works.
There are many possible ways to establish a self-supervised framework for visual representation learning. Conventional methods have mostly focused on hand-crafting a “pretext task” that is similar conceptually to the language modeling task employed by self-supervised NLP models. The network is trained by predicting the objective as defined by these pretext tasks, and the visual representations are learned as a by-product in the process. These methods include relative patch prediction18, jigsaw puzzles19, colorization20, etc. More recently, pixel prediction21 has been used to train a GPT model to learn visual representations. These works have relied on heuristics to hand-craft a pretext task that is often intuitive for visual information but otherwise sub-optimal as a learning framework.
The pretext tasks were subsequently surpassed by a class of self-supervised learning methods known as contrastive learning that dates back to Hadsell et al6 in 2006. Although contrastive learning literature sometimes uses the term “pretext task” as well, it no longer refers to any explicit prediction task by which the network is trained. Indeed, as showed in SimCLR13 recently, pretext tasks could be subsumed by various data augmentations employed in the contrastive framework.
Let’s begin the introduction of contrastive learning framework with a seemingly odd angle: word embeddings. Mikolov et al1 energized this sub-field of NLP in 2013 by popularizing the word2vec framework, in which the goal is to learn high quality vector representations of words (“word embeddings”) through self-supervised training of neural language models. Stripping away the technicalities, the central problem of the framework is to model a conditional probability distribution of a target \(w\) given a context \(c\), as an energy-based softmax function:
\[P_\theta(w \vert c)\gets\frac{\exp(s(w,c)/\tau)}{\sum\limits_{w'\in V}\exp(s(w',c)/\tau)}\]Note that both \(w\) and \(c\) are vector representations transformed from data samples through parameterized encoders, \(w\gets f_\theta(x)\). Here \(s(w,c)\) is known as a score function, which measures the “similarity” between the target and the context; in simplest form, as in word2vec, it can be an inner product between the two vectors. The denominator term, which is a summation over all possible targets \(w'\), is known as the partition function. This term serves to normalize the function as a probability distribution over the “vocabulary”, which is implicitly assumed to be a set of discrete tokens in the expression.
The model is trained by maximizing the log-likelihood. If the vocabulary could be treated as discrete, then the problem could be formulated as a multi-class logistic regression over the vocabulary. Maximizing the log-likelihood would be equivalent to minimizing the categorical cross-entropy loss between the model’s prediction and the ground truth, resulting in an objective function as:
\[J(\theta)\gets\mathbb{E}_{w,c}[-\log P_\theta(w \vert c)]\]In practice the expectation could be approximated by averaging over the entire training set, a mini-batch, a fixed-size window, or fully on-line.
To put the above formulation into perspective, take as an example the Skip-gram, one of more popular methods in word2vec. In Skip-gram, the context and the target are chosen as representations of the current word token \(w_I\) and a nearby word token \(w_O\), respectively. It models a conditional probability distribution over the entire vocabulary of words (which is discrete) that represents the likelihood of \(w_O\) appearing in the context of \(w_I\). In other words, the pretext task* for training Skip-gram is to predict \(N\) words around the current word in an input sentence. The objective function is thus naturally an average over a fixed-size window, which is the length of the prediction.
Having formulated the self-supervised framework as modeling a conditional probability distribution from the NLP perspective, let’s turn to the problem in the context of CV. An obvious question is: what is the “vocabulary” for visual representations? Unlike texts, which consist of discrete tokens of words, the visual representations for images are over continuous spaces. This has been a major difficulty for self-supervised learning of visual representations. Intuitively, one can go the the extreme and treat each image in the dataset as a discrete entity of the visual “vocabulary”. The objective is thus to learn a representation for each image, and the problem can now be formulated almost exactly as the word2vec example. This is the insight behind InstDisc2, short for “instance discrimination”. The importance of InstDisc is that it pioneered training of deep neural networks by a class of self-supervised methods known as contrastive learning3, the current leading paradigm in self-supervised visual representation learning.
In InstDisc, an encoder network \(f_\theta\) maps an image \(x_i\) into a representation vector \(v_i\gets f_\theta(x_i)\) in the latent space. The conditional probability of \(P_\theta(v_i \vert v)\) is modelled as a measure for the “similarity” between representations \(v_i\) (target) and \(v\) (context) of two images (visual instances). The model is trained to minimize the negative log-likelihood objective \(J(\theta)\), same as before. In other words, InstDisc can be seen as learning visual representations in a way that maximizes the similarities between all images in the training set.
The above formulation faces a major challenge in practice: the evaluation of the partition function in the softmax could become prohibitively expensive, due to the huge size of the vocabulary; for NLP it is the number of words, for CV it is now the size of the dataset, which could be in millions. Fortunately, there have been several established methods to tackle this general problem of softmax-based models. Bengio & Senecal4 proposed to use Importance Sampling with Monte-Carlo estimate to compute gradients of the softmax. The original Skip-gram paper used hierarchical softmax5 with Huffman trees, while the later work word2vec subsumed Skip-gram and proposed to use the Negative Sampling1 (NEG) technique. NEG is a simplification for the special purpose of learning word embeddings from a general approach known as Noise Contrastive Estimation6 (NCE), which is adopted by InstDisc. Since NCE is behind some of the recent major works on contrastive learning7, it warrants a closer look in this context.
Noise Contrastive Estimation
The target of NCE is to estimate the empirical data distribution, \(\tilde{p}(v \vert c)\), by the parameterized model \(P_\theta(v \vert c)\), where \(v\) is visual representation of a sample and \(c\) is the context. Instead of finding smart ways to evaluate the partition function, NCE framework avoided the hurdle altogether by reformulating the problem into a binary logistic regression task. This is done in the following steps (for a more detailed treatment please refer to the notes by Chris Dyer):
-
Generate a two-class dataset
NCE begins by assuming a noise or “proposal” distribution, \(q(v)\), with which a set of \(m\) “negative” samples \(\{v^-\}\) are drawn from the original dataset. In practice this is usually chosen as the uniform distribution, in which case the negative samples are drawn at random. These samples carry with them a label \(D=0\) indicating that they are negative samples drawn from the noise distribution. Next we draw a “positive” sample \(w^+\) from the empirical distribution \(\tilde{p}(v \vert c)\) and label it with \(D=1\); in practice, algorithms typically treat the current image or its views as the positive sample. There are several ways to generate the negative samples, and how to obtain good quality negative samples remained a vigorously researched topic for contrastive learning methods.
-
Model \(h_\theta(v,c)=P(D=1 \vert v,c)\), the conditional probability of the label \(D\) being positive given the sample \(v\) and context \(c\)
Within the two-class dataset, it is easy to first write the joint probability of \(P(D,v \vert c)\) as follows:
\[\begin{split} P(D=1,v \vert c)&=\frac{1}{1+m}\cdot\tilde{p}(v \vert c)\\ P(D=0,v \vert c)&=\frac{m}{1+m}\cdot q(v) \end{split}\]And since there are only two classes:
\[P(v \vert c)=P(D=1,v \vert c)+P(D=0,v \vert c)\]Using the laws of conditional probability, \(P(D \vert v,c)=\frac{P(D,v \vert c)}{P(v \vert c)}\), we obtain:
\[\begin{split} P(D=1 \vert v,c)&=\frac{\tilde{p}(v \vert c)}{\tilde{p}(v \vert c)+m\cdot q(v)}\\ P(D=0 \vert v,c)&=\frac{m\cdot q(v)}{\tilde{p}(v \vert c)+m\cdot q(v)}=1-P(D=1 \vert v,c) \end{split}\]Now model the conditional probability by parameterizing the empirical distribution \(\tilde{p}(v \vert c)\sim f_\theta(v,c)\):
\[P(D=1 \vert v,c)\sim\frac{f_\theta(v,c)}{f_\theta(v,c)+m\cdot q(v)}=h_\theta(v,c)\] -
Formulate the NCE loss function \(L_{NCE}\)
The task is now a binary logistic regression to classify a given pair \((v,c)\) in the sample as positive (\(D=1\)) or negative (\(D=0\)). The model can be trained using the cross-entropy loss between the model’s prediction \(h_\theta(v,c)\) and the ground truth \(D\). For a positive pair \((v^+,c)\):
\[L_{Xent}(v^+)\gets-\log h_\theta(v^+,c)\]For a negative pair \((v^-,c)\):
\[L_{Xent}(v^-)\gets-\log(1-h_\theta(v^-,c))\]The objective function for the training should ideally be summarizing the losses over all possible positive and negative samples, i.e., the losses should take the expectation over the perspective sampling distributions:
\[L\gets-\mathbb{E}_{w^+\sim \tilde{p}}[\log h_\theta(v^+,c)]-m\cdot\mathbb{E}_{v^-\sim q}[\log(1-h_\theta(v^-,c))]\]Here the loss for negative samples is multiplied by \(m\) as we assumed there to be \(m\) times more negative samples in the dataset. In practice, the training is usually done through mini-batch SGD, in which case the expectation for positive sample is replaced by a single loss on the current positive sample, and the expectation for the negative samples could be approximated by a Monte-Carlo estimation with \(\mathbb{E}\sim\frac{1}{m}\sum_{i=1}^m\).
The final objective function \(L_{NCE}\) for a mini-batch \(\mathcal{B}\) is then:
\[L_{NCE}\gets\sum_{w\in\mathcal{B}}\left(-\log h_\theta(v^+,c)-\sum\limits_{i=1}^m\log(1-h_\theta(v_i^-,c))\right)\]
By re-casting the problem as binary classification, the NCE framework was able to train a model of the empirical distribution \(\tilde{p}(v \vert c)\) without the softmax partition function. Notice here that the context \(c\) is not always necessary for learning visual representations, and NCE is still applicable without the it by simply removing all \(c\)’s in the above formulations. This is the case in InstDisc, where there is no context representation, the positive and negative samples are contrasted directly by minimizing the NCE loss. A later work PIRL8 adopted the NCE framework in InstDisc, with additional context representation. In PIRL, the current image \(v_I\) and all other images \(v_{I'}\) in the batch form the positive and negative samples, respectively; the context is a transformed view of the current image \(v_I^t\).
Contrastive Loss Function
Although InstDisc introduced NCE as a computational trick, the framework has quickly morphed into a generalized paradigm for self-supervised visual representation learning, known as contrastive learning. Dating back to Raia Hadsell et al3 in 2006, contrastive learning framework is characterized by its use of a contrastive objective function between positive and negative samples.
The objective functions used by most of the recent major contrastive learning methods, including CPC9,10, MoCo11,12, SimCLR13, InfoMax14, etc., are all based on an alternative formulation of the NCE loss known as the InfoNCE loss function, first proposed and best illustrated by the CPC paper. Although each of the works used a distinctive “flavor” for their losses, in essence they can all be expressed abstractly in the following form:
\[L_{InfoNCE}\gets\sum\limits_{v\in\mathcal{B}}-\log\frac{\exp(s(v^+,c)/\tau)}{\sum\limits_{v\in\mathcal{V}}\exp(s(v,c)/\tau)}\]The denominator is a summary over a sample set \(\mathcal{V}\), comprising of positive and negative pairs; usually there is one positive pair and multiple negative pairs. \(s(v,c)\) is a score function. The loss is a summary over a mini-batch \(\mathcal{B}\) of training samples that could contain multiple sample sets \(\mathcal{V}\).
At a glance this looks exactly like the conditional probability distribution model at the beginning of the post, but a critical difference is that the partition function here is no longer summary over the entire visual vocabulary, but just the sample set. It also differs from the original NCE formulation in that it no longer requires an explicit noise distribution, and the loss function also has a much simpler form. InfoNCE loss is formulated differently in that it is not aiming at modeling an empirical conditional probability function directly as before; instead, it aims to model a ratio between the empirical distribution \(\tilde{p}(v \vert c)\) and the noise distribution \(q(v)\). With this premise, it can be shown that the InfoNCE loss arises naturally from the NCE framework, by following the same steps and casting the problem as a multi-class logistic regression instead of a binary one:
From step 2 in the NCE framework, we now aim to model \(P(D=i \vert V,c)\), the conditional probability of the \(i\)-th sample \(v_i\) being the positive sample in the sample set \(\mathcal{V}\). By rules of conditional probability we can write9:
\[P(D=i \vert V,c)=\frac{P(D=1 \vert v_i,c)\prod\limits_{l\ne i}^\mathcal{V}P(D=0 \vert v_l,c)}{\sum\limits_{v_j\in\mathcal{V}}\left(P(D=1 \vert v_j,c)\prod\limits_{l\ne j}^\mathcal{V}P(D=0 \vert v_l,c)\right)}\]The numerator represents the joint probability of sample \(v_i\) being positive and all other samples being negative. We can re-organize the product term in the numerator by:
\[P(D=1 \vert v_i,c)\prod\limits_{l\ne i}^\mathcal{V}P(D=0 \vert v_l,c)=\frac{P(D=1 \vert v_i,c)}{P(D=0 \vert v_i,c)}\prod\limits_{v_l\in\mathcal{V}}P(D=0 \vert v_l,c)\]The product term now includes the positive sample \(v_i\). Similarly this procedure could be done for each of the entries in the denominator as well, which cancels out with the product term in the numerator. The conditional probabilities are readily available from the previous NCE framework, and can be substituted as:
\[\frac{P(D=1 \vert v_i,c)}{P(D=0 \vert v_i,c)}=\frac{1}{m}\frac{\tilde{p}(v_i \vert c)}{q(v_i)}\]Previously in NCE, the empirical distribution \(\tilde{p}(v \vert c)\) is modeled by \(f_\theta(v,c)\); now we model the ratio instead as \(\tilde{p}(v \vert c)/q(v)\gets f_\theta(v,c)\). Finally:
\[P(D=i \vert V,c)\sim\frac{f_\theta(v_i,c)}{\sum\limits_{v_j\in\mathcal{V}}f_\theta(v_j,c)}\]The problem could now be casted as a multi-class logistic regression, each sample in the data set representing a distinctive class. The categorical cross entropy loss would leave only the positive sample term, while all negative sample terms are zero, as:
\[L_{Xent}\gets-\log\frac{f_\theta(v^+,c)}{\sum\limits_{v_j\in\mathcal{V}}f_\theta(v_j,c)}\]Summarizing the losses over a mini-batch would give the InfoNCE loss as formulated previously.
Contrastive Learning
The InfoNCE loss is simple to implement in practice and clear in its contrastive format, making it an attractive objective function for contrastive learning. A series of works have emerged following a similar paradigm of InstDisc and CPC. They share a common contrastive learning framework that could be characterized as follows:
Data augmentation. An image in the dataset is first transformed by a string of various data augmentations into what would be known as a view in the contrastive learning literature. Data augmentations are of central importance to contrastive learning, in that: a) combination of data augmentations can effectively subsume a “pretext task”13; b) choice of the data augmentation pipeline has significant impact on the quality of the learned representations. In SimCLR13, the authors presented extensive ablation studies on the effectiveness of 10 most commonly used data augmentations, including:

image source: SimCLR
One possible reason for the impact of data augmentations on visual representations is perhaps the nature of the visual data. Unlike texts, which consist of invariant word tokens, the raw visual input as images or videos can come in various formats in terms of their resolution, color channels, intensity, etc.. In other words, the raw visual data is very noisy; learning visual representations from a noisy data set would require special care at noise filtering. In practice, the algorithm can work with fixed data augmentation pipelines that are deemed effective, or by stochastically sampling random data augmentations for each view.
View selection. The transformed views are selected as the context (optional), the positive or negative samples. A simple selection scheme is to assign the view from the current image as the positive sample, and views from all other images in the same batch as negative samples. There can also be multiple views through different augmentation pipelines from the same image, including the original, which can be seen as a view through identity transformation. CPC9,10 is different from other works in this regard by leveraging spatial correlations, in that the views from a single image are from cropped patches at different grid locations, and the context is an autoregressive summary over multiple views.
Sample generation. One big challenge for contrastive learning is that it requires a large number of negative samples for one positive sample in training. The simple way is to use all other views in the same batch as negative samples, e.g., SimCLR. Although effective, this would limit the pool of accessible negative samples by the batch size. Another common approach is to store the views from previous batches in a memory bank2, from which the negative samples could be drawn for the current iteration. A similar method is called memory queue11, which functions the same way as a memory bank, but differs in that it stores the encoded representations of views instead.
Model architecture. The parameterized network \(f_\theta\) usually consists of two parts. Firstly, a neural network base encoder transforms the views into visual representations in the latent space. A typical choice for the encoder architecture is ResNet, and it has been shown empirically10 that scaling up the dimension (depth, width, or receptive field) of the encoder network can improve the quality of learned representations. There have been few works that explored using a better supervised learning architecture, for instance EfficientNet, as the base encoder in contrastive setting. Secondly, the learned representations are projected and contrasted by a neural network projection head, which serves as a score function to produce the contrastive loss. The projection head could be an MLP with hidden layers or simply a linear layer. The networks for positive and negative samples are usually shared and could be trained by standard mini-batch backpropagation, with the exception of MoCo11,12, due to its memory queue which stores encoded representations from previous mini-batches. To circumvent this complication, the authors proposed to train the negative encoder separately by momentum update.
Contrastive loss. Currently, InfoNCE or its variants are the most widely used contrastive loss functions. Theoretical justification for this loss function has mostly been centered around a concept known as the mutual information. Minimizing the InfoNCE loss has been shown to be equivalent to maximizing a lower bound on the mutual information between views9,15. As such, the contrastive learning community has yet to be convinced of the MI hypothesis. Tschannen et al16 showed that with a stricter lower bound on the mutual information, the model could empirically learn worse representations. The authors also pointed to a connection between InfoNCE and deep metric learning, in the special case where the model employs symmetric encoders for positive and negative samples as well as a symmetric score function (dubbed “critic” in the paper; simple inner product would be an example of a symmetric critic). Despite the lack of solid theoretical justifications, works based on InfoNCE have been repeatedly shown to excel in practice. There have been few works that explored other choices for the contrastive loss.
In practice, contrastive learning models are typically trained on unlabeled datasets with large amounts of samples and rich visual semantics, such as the ImageNet. The networks are trained by stochastic gradient descent, although more recent works have opted to use more sophisticated optimizers than Adam or SGD. SimCLR and BYOL17 both used the LARS optimizer for the availability of large batch sizes (up to 32K). The downside of contrastive learning is perhaps that it is now even more costly to train, as these methods typically require training over hundreds of epochs with large batch sizes.
One might also expect a more versatile choice of views from contrastive learning methods. In particular, it would be interesting to contrast between the objects detected in images, compared to contrasting between images. The hypothesis behind this rationale is that the visual representations for objects would be better defined than that of images, which contain any number of objects with background noises. It might be worthwhile to integrate the object detection protocols into self-supervised visual learning in general.
Evaluation Protocols
Although the main features of the contrastive learning framework have been more or less established through a string of major works published in the last two years, the field remains in rapid shifting for design choices. These innovations would require comprehensive benchmarking on the quality of the learned visual representations. Several commonly adopted protocols include: linear evaluation, semi-supervised learning, transfer learning.
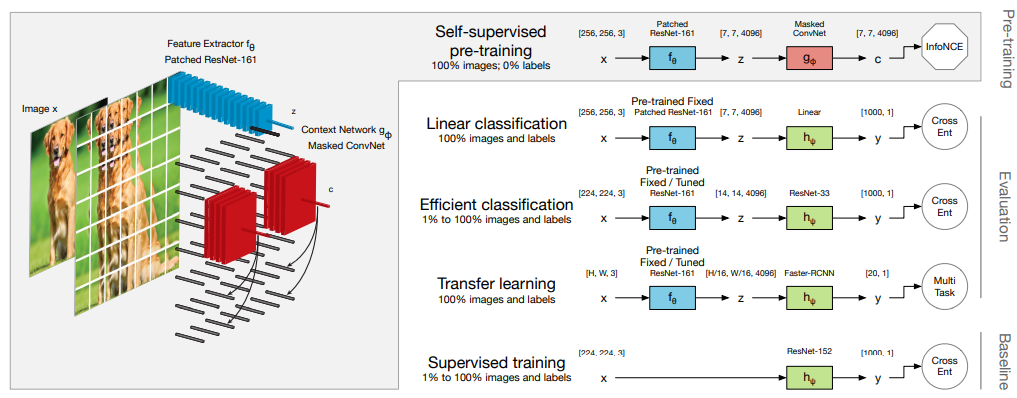
image source: CPC-v2
Linear evaluation works by assuming that a better visual representation would be more linearly separable. Although there have not been sufficient justifications as to why this should be the case, this protocol has become widely adopted by self-supervised learning community in general. Part of the reason could be that it is simple to implement in practice. The learned visual representations are directly used as inputs to a linear classifier, e.g., an additional linear layer to the output of the encoder network, whose weights are now frozen during subsequent training. The classifier is trained on the training set by standard supervised learning, and the test set accuracy is reported as the linear evaluation performance of the learned representations. Since most of the network’s parameters are now frozen during training, linear evaluation would be very fast compared to the other protocols. These results using a linear classifier have already been impressive (76.5%13 top-1 on ImageNet) for contrastive learning. However, linear evaluation are not always predictive10 of performances on more critical benchmarks, such as transfer learning.
Semi-supervised learning is also referred to as fine-tuning or efficient training in the contrastive learning literature. The contrastive learning is viewed as a pretraining phase, and the model is subsequently trained by supervised learning, but with a fraction of labeled data in the training set. Typically 1% and 10% labeled data training results are reported. The encoder network’s parameters are now trained simultaneously with the added classification heads. The leading contrastive learning methods now boast competitive or superior ImageNet accuracy compared to supervised learning counterparts with similar network architecture/complexity trained with the same number of labeled data10,13. However, they have yet to achieve competitive accuracy against the state-of-the-art supervised models trained with the full labeled data. A solid semi-supervised learning comparison between contrastive methods would require additional supervised baselines to exclude the noise from network architectures: a) by training the network without contrastive pre-training on the full labeled dataset; b) by training the learned network with 100% labeled data.
Transfer Learning typically evaluates the learned representations by attaching a custom prediction head to the output of the encoder network. Choice for the prediction head would depend on the nature of the downstream visual tasks. The evaluation then follows typical transfer learning protocol by fine-tuning the full network’s parameters on individual datasets through supervised training. Beyond classification on datasets such as CIFAR, Cars, Birdsnap, etc., contrastive learning methods have also been benchmarked by object detection datasets such as PASCAL and COCO.
Other evaluation protocols include unsupervised learning by SVM or kNN2, but they are less popular in the community.
Semi-supervised learning is perhaps the most significant protocol for contrastive learning (and self-supervised learning in general), as it directly tests the main promise of self-supervised learning to alleviate the need of large amounts of labeled training data. In this regard, the competitive performances of leading contrastive methods on training with as low as 1% of labeled data is very promising.
Baselines
Although contrastive learning is not the only promising framework in self-supervised learning, the strong performances from the recent slew of works have nonetheless established themselves as major baselines, for not only self-supervised learning, but also any attempt in general that aims at reducing the need for labeled data. Below is a figure from SimCLR13 that listed some of the major contrastive baselines by their linear evaluation performances:
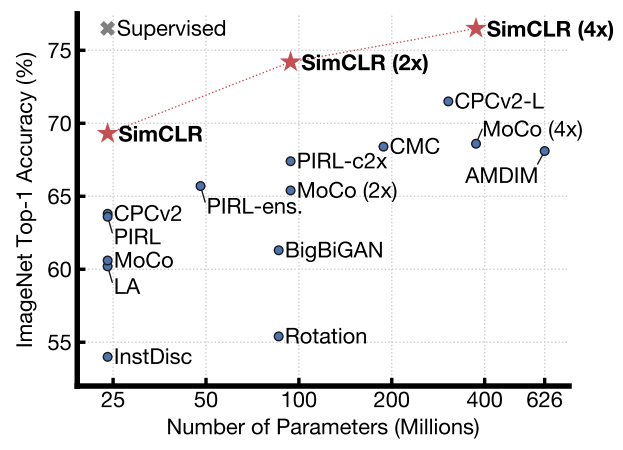
image source: SimCLR
InstDisc2. This is one of the first works that used contrastive learning to train convolutional neural networks. It proposed to use a memory bank to store views from previous batches as a pool to draw random negative samples, an approach that was adopted by several later works. The NCE loss was used as the training objective. The authors didn’t emphasize on data augmentations, instead they simply used the original images as the views. The lack of sophisticated data augmentations clearly limited the quality of the features. Interestingly, the paper did not insist on the learned representations being linearly separable. InstDisc was able to achieve a 54.0% top-1 accuracy on ImageNet with a ResNet-50 architecture by training an SVM classifier on top of the learned encoder.
PIRL8. Dubbed as “Pretext-Invariant Representation Learning”, this paper is similar to InstDisc in that: a) uses an NCE loss (formed as convex combination with an auxiliary term); b) selects the original images as positive or negative samples without data augmentation; c) uses memory bank to draw negative samples (the bank stores representations instead of views from other batches; similar to MoCo). PIRL provides an additional context to the contrastive loss: the view from a positive sample. The authors rationalized this choice by hypothesizing that the method would become less variant to different data augmentations. The augmentations used to generate the views are sampled at random from a set of transformations, such as re-shuffling of patches, rotation, etc.. In particular, the authors conducted experiments on a jigsaw-puzzle transformation which leverages spatial correlation within an image.
An interesting side note on PIRL: the loss function in this paper is an NCE loss, however the authors framed the network in a way that it actually models the InfoNCE conditional probability ratio. For the NCE loss there is also no specific proposal distribution mentioned. Am I missing something here?
CPC. Short for “Contrastive Predictive Coding”, CPC9 pioneered the InfoNCE loss function. Compared to other contrastive methods, this work is unique in several ways. It leverages spatial co-occurrence at patch-level, by cropping the image into a grid of patches. The views from these patches are selected as the positive or negative samples. CPC framework also uses a distinctive context for loss function, by summarizing the views “prior” to the positive sample (the patch at “current” grid position) autoregressively. This formulation resembles pretext tasks for sequential data, such as audio waves or texts; indeed, the authors have demonstrated that the CPC method could be adapted to various modalities other than visual information.
A later work dubbed CPC-v210 subsequently improved the baseline linear evaluation results (on image domain in particular) by up to +23% in absolute performance on ImageNet. The improvements are cumulated through: a) increased model capacity in depth, width and receptive field size (patch size); b) layer normalization; c) ensembled autoregressive spatial predictions for all four directions; d) extensive patch-level data augmentations. At publication, CPC-v2 achieved the state-of-the-art at 71.5% top-1 accuracy with a large ResNet-161 model.
MoCo11,12. The “Momentum Contrast” papers proposed to generate two views from a single image under different random data augmentations. The views are subsequently projected into latent space through two networks, a query network and a key network. The query network processes the context, while the key network processes positive and negative samples. The negative samples are drawn from a memory queue, which is similar to the memory bank but stores representations rather than views from previous batches. To train the key network, the authors proposed a momentum update rule as: \(\theta_k\gets m\theta_k+(1-m)\theta_q\); the parameters of the query network are optimized by standard stochastic gradient descent. Notice that the momentum update essentially makes the key network a slowly-moving average of the query network, an insight that was also shared by the latest state-of-the-art BYOL17.
SimCLR13. In this paper, the authors put their focus on the data augmentations. Through comprehensive empirical study of various combinations of data augmentations, SimCLR proposed to use a 3-step pipeline that comprises: a) random crop + resize into standard resolution; b) random color distortion; c) Gaussian blur. The paper largely adopted best practices from existing knowledge: contrast between two views from a single image as the context and positive / negative samples, following MoCo; use large batch sizes to draw sufficient number of negative samples; formulate the problem with InfoNCE loss (dubbed NT-Xent or normalized temperature-scaled X-entropy in the paper); use MLP with one hidden layer as the projection head. The combination of an effective data augmentation pipeline and a solid contrastive framework in this paper contributed to the state-of-the-art 76.5% top-1 linear accuracy among contrastive learning methods (BYOL has a +2% absolute gain, but it is not a contrastive framework). The results are equally impressive when trained with just 1% of labeled data from ImageNet (85.8% top-5 accuracy), surpassing the supervised learning baseline (ResNet-50 trained with same fraction of labeled data) by a large margin.
Conclusion
This post introduced the contrastive learning framework along with its major baselines. Are these methods the future of self-supervised learning, at least for visual representations? Although very promising, the contrastive learning framework still suffers from lack of sound theoretical grounding, a clear understanding of the learned visual representations, as well as practical challenges such as the growing batch sizes and the training costs. Alternative frameworks have also attained performances on par with contrastive learning. For instance, a recent work from DeepMind, dubbed BYOL, eliminated the contrastive framework altogether by using a Deep Q-learning style bootstrapping scheme to train the encoder: the network is trained to approach a moving average from previous iterations. The impressive results obtained through such a simple and counter-intuitive framework would certainly inspire more explorations in the near future. An even larger question would be, can any self-supervised method bring to the CV domain a similar paradigm shift as the pretrained language models had brought to the NLP?
Reference
- Tomas Mikolov et al, “Distributed Representations of Words and Phrases and their Compositionality”, NeurIPS 2013
- Zhirong Wu et al, “Unsupervised Feature Learning via Non-Parametric Instance Discrimination”, CVPR 2018
- Raia Hadsell et al, “Dimensionality Reduction by Learning an Invariant Mapping”, CVPR 2006
- Yoshua Bengio & Jean-Sebastien Senecal, “Quick Training of Probabilistic Neural Nets by Importance Sampling”, AISTATS 2003
- Frederic Morin & Yoshua Bengio, “Hierarchical Probabilistic Neural Network Language Model”, AISTATS 2005
- Michael Gutmann & Aapo Hyvarinen, “Noise-contrastive estimation: A new estimation principle for unnormalized statistical models”, AISTATS 2010
- Xiao Liu et al, “Self-supervised Learning: Generative or Contrastive”, Arxiv 2020
- Ishan Misra & Laurens van der Maaten, “Self-Supervised Learning of Pretext-Invariant Representations”, CVPR 2020
- Aaron van den Oord et al, “Representation Learning with Contrastive Predictive Coding”, Arxiv 2018
- Olivier J. Henaff et al, “Data-Efficient Image Recognition with Contrastive Predictive Coding”, Arxiv 2020
- Kaiming He et al, “Momentum Contrast for Unsupervised Visual Representation Learning”, CVPR 2020
- Xinlei Chen et al, “Improved Baselines with Momentum Contrastive Learning”, Arxiv 2020 (Technical Report)
- Ting Chen et al, “A Simple Framework for Contrastive Learning of Visual Representations”, ICML 2020
- R Devon Hjelm et al, “Learning Deep Representations by Mutual Information Estimation and Maximization”, ICLR 2019
- Yonglong Tian et al, “What Makes for Good Views for Contrastive Learning?”, Arxiv 2020
- Michael Tschannen et al, “On Mutual Information Maximization For Representation Learning”, ICLR 2020
- Jean-Bastien Grill et al, “Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning”, Arxiv 2020
- Carl Doersch et al, “Unsupervised Visual Representation Learning by Context Prediction”, ICCV 2015
- Mehdi Noroozi & Paolo Favaro, “Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles”, EECV 2016
- Richard Zhang et al, “Colorful Image Colorization”, EECV 2016
- Mark Chen et al, “Generative Pretraining from Pixels”, ICML 2020