iGPT: A Curious Case of Self-Supervised Learning
This blog post briefly reviews the paper “Generative Pretraining from Pixels” by Mark Chen et al, one of the ICML 2020 best paper award candidates. In this work, the authors constructed a new sequence pretraining task by resizing and reshaping a 2D image into a 1D sequence of pixels. Using this sequence as the input, GPT-2, the highly successful pretrained language model consisting primarily of self-attention modules, is then pretrained in a self-supervised manner by predicting pixels. The paper largely follows widely used paradigms in modern natural language processing. In particular, the authors investigated the effects of both the auto-regressive and the denoising auto-encoding pretraining objectives. In evaluation, the paper reports results obtained through linear probing by treating the pretrained model as a feature extractor, as well as through full fine-tuning, the standard paradigm of transfer learning for image tasks.
In his keynote speech at AAAI 2020 conference, Yan LeCun described self-supervised learning as “learning to predict parts of the input from other parts of the input”. Previously, methods that fall into this category had been loosely referred to as unsupervised learning or semi-supervised learning. But recently, it has become more widely accepted that the term self-supervised learning best describes this emerging paradigm, partly due to the fact that the learning process works very similar to supervised learning in that an implicit label (which is the parts of input being predicted) is used as the target of prediction.
Self-supervised learning has long promised to alleviate the need of large amounts of labelled data to sufficiently train a deep learning system, one of the three major challenges facing supervised learning that Yan LeCun raised in the same keynote speech. In recent years it has begun to gain significant attention in the field of deep learning, partly due to the success of pretrained language models such as the GPT family1,2, BERT3 and XLNet4, in the domain of natural language processing. These transformer-based5 neural networks partly owe their success to a family of self-supervised learning methods called generative pretraining: they are first pretrained on large corpus of unlabelled texts by generating predictions for some of the word tokens in the input sequence, then fine-tuned or used (less commonly) as feature extractors on downstream tasks.
The central question to a self-supervised learning method is the training objective; or in LeCun’s words, how to formulate the problem of predicting parts of the input from other parts of the input. While a curated review of the spectrum of self-supervised training objectives is undoubtly beyond the scope of this post, it is pertinent to introduce two of the most widely used objectives particularly in NLP domain, as both have been thoroughly investigated in this paper. The auto-regressive objective seeks to predict the next element in an input sequence by conditioning the network on the previous elements. The auto-encoding (more precisely, the denoised auto-encoding or simply the BERT) objective, on the other hand, tries to predict the missing elements in a corrupted input sequence. The following illustration from this paper provides a good pedagogical picture of the two objectives:
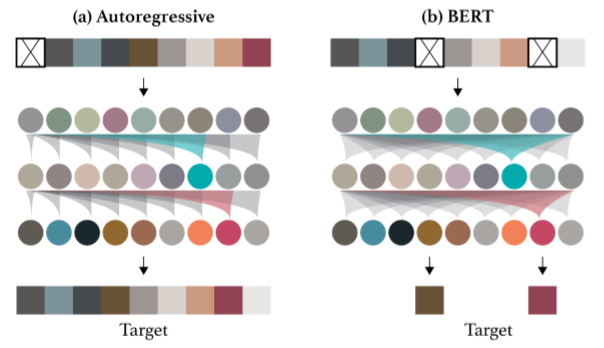
image source: iGPT paper
Formally, given an unlabelled input sequence \(X=(x_1,x_2,...,x_n)\) and density distribution \(p(x)\), AR objective minimizes the negative log-likelihood of the density:
\[L_{AR}=\mathbb{E}_{x\sim X}[-\log p(x)]\]where the expectation is over all the elements in the input sequence. The density could be modelled by conditioning the probability for the current element auto-regressively on the probabilities of previous elements in the sequence:
\[\begin{split} p(x)=\prod\limits_{i=1}^np(x_{i}|x_{1},...,x_;\theta) \end{split}\]In NLP practice, usually the input sequence is first permutated to reorder the sequence, or in the extreme case of XLNet4, an expectation is taken over all possible permutations. In this work, the input is generated by breaking a 2D image into a 1D sequence of pixels, the authors opted to adopt the original, unpermutated sequence, a.k.a. the raster ordering.
The AE objective could be formulated as to minimize the sum of the negative log-likelihoods:
\[L_{AE}=\mathbb{E}_{x\sim X}\mathbb{E}_{M}\sum_{i\in M}[-\log p(x_i|x_{[1,n]\setminus M})]\]where \(M\) is called the input mask or BERT mask (as it is popularized by the paper), which is a subset of [1, n] such that each index i has a certain (low) probability of appearing in the subset. The network is trained to receive the input with the masked elements excluded. In practice this is usually done by simply zeroing the elements of the corresponding positions. The conditional probability represents the fact that the probability density of element \(x_i\) is conditioned on the masked input. Note that recovering the corrupted input is conceptually similar to denoising auto-encoders.
Both the AR and AE training objectives are rooted in language modeling, one of the fundamental problems in natural language processing. In language modeling, a system is tasked with generating the next word or word token in a sequence. Later it was proposed by Mikolov et al6 that a neural network could be trained with language modeling objectives to produce powerful word embeddings. Their CBOW model is trained by what might now be referred to as the auto-regressive objective, albeit they conditioned the probability on not only the past but also the future elements, while their more popular skip-gram model is trained by a slightly different form of auto-encoding objective.
The research of word embeddings have exploded since then and helped to propell self-supervised pretraining to become the dominant paradigm in modern NLP models. GPT1 was the first major work that incorporated the transformer network with self-supervised pretraining, by using the vanilla AR objective. To better suit the pretraining objective, self-attention masks were invented to cope with the input ordering, as is adopted in this work, replacing the positional encodings proposed by the original transformer5. BERT3 was the first major work to adopt the denoising auto-encoding objective, in the form of a masked language modeling task.
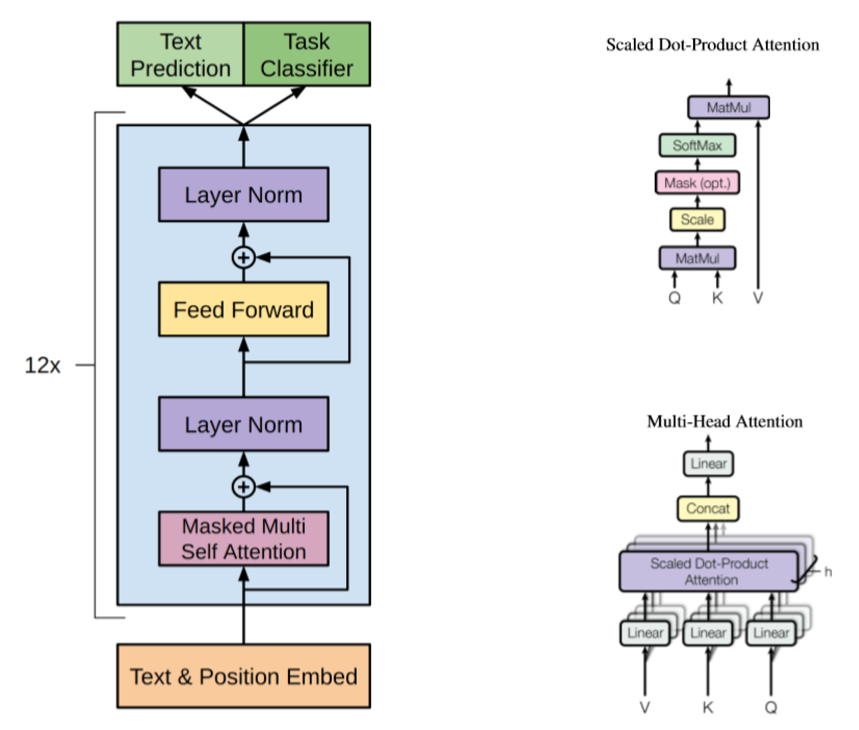
Figure: (left) GPT architecture (image source: GPT paper); (right) Multi-head self-attention module (image source: Transformer paper)
How to transfer the pretrained models to perform on downstream tasks? At least for NLP tasks, but perhaps also to a more general extend, methods typically fall into two categories: fine-tuning or feature extraction. Note that both method rely on supervised learning with labelled downstream datasets, hence the name semi-supervised learning had also been used to describe this paradigm. In fine-tuning, the pretrained models are directly adapted to a downstream dataset with minimal architectural modifications, but otherwise untethered. The model is then trained in a supervised manner with all parameters being trainable, with the pretraining serving in essence as an initialization or a regularization phase. In feature extraction, the pretrained model is treated as a feature extractor; the features produced by the model, not the model itself, is what’s being transferred to downstream dataset. In this work, feature extraction is done by linear probing, where a linear classifier (e.g., a single FC layer) takes as input the features produced from the pretrained model, which is now conditioned on the downstream data. The idea is that the quality of feature extractors could be evaluated by its abiliity to generate linearly separable features.
In this work, authors had investigated and compared the results obtained through both fine-tuning and linear probing. Intuitively, fine-tuning might provide better final performance on a specific task, but linear probing would be faster if the goal is to evaluate pretraining performance. These two methods differ primarily in the following aspects:
- in fine-tuning all the parameters in the network are trainable, while in linear probing the pretrained model’s parameters are freezed
- in fine-tuning the pretrained models undergo minimal architectural change, while in linear probing the transferred features are not necessarily from the last layer of the pretrained models, but might also (as in this work) be from intermediate layers (in which case the subsequent layers in the pretrained models could be viewed as dicarded during transfer)
The aforementioned training objectives and transfer methods are all rooted in NLP domain. I titled this post as a curious case of self-supervised learning, partly due to the fact that iGPT is the first major work that seeks to apply the standard NLP self-supervised paradigm to image domain. There have been several prior works on self-supervised training for images, but most if not all of these methods, including prominent ones such as DeepInfoMax7 and MoCo8, are based on contrastive pretraining, rather than the generative pretraining investigated in this paper. Instead of training to generate predicitions for parts of the input, in constrastive learning the model is trained to discriminate (‘constrast’) between similar and dissimilar features. There are various methods to generate the features for constrasting, for instance by selecting positive and negative samples or by corrupting parts of input samples, as well as various formulations of the constrastive learning objective function, based on the Noise Contrastive Estimation formula9. In the recent work SimCLR10, one of the major benchmarks used in the iGPT paper, researchers from Google used simple data augmentations to generate various views of the same input image, then encode these views through a ResNet-based convolutional neural network to produce different features. The network is pretrained on ImageNet without the labels to maximize the contrast between views produced by different input images, while simultaneously to minimize the discrimination between different views of the same input image. This blog from Google provides a detailed introduction to SimCLR.
Evidently, constrastive pretraining is very different from the generative pretraining methods, and while both being self-supervised learning methods, perhaps constrastive learning is more suitable intuitively for image domain. The main theoretical difficulty, as put forth by Hinton and LeCun at various occassions recently, lies with the fact that images (and by extension, videos) are much harder to model as probabilitistic distributions, which is what generative objectives seek to model. Put it simply, there is a huge range of possible segments to fill in a missing blank in an image. This is why, and perhaps taking inspirations from GANs (which successfully models probabilistic distributions over images), that LeCun had proposed to use latent variable based methods to improve generative pretraining on images in his AAAI 2020 keynote speech.
The iGPT paper investigated a different, in some sense more naive approach to the same problem. By breaking a 2D image into a 1D sequence of pixels, the authors had reduced the problem of modeling probabilities of images into modeling probabilities of pixels in a one dimensional sequence, which is itself a computationally more expensive (due to large image resolutions) but otherwise prototypical NLP problem. The paper reports experimental results obtained by pretraining with both the AR and AE objectives on ImageNet, as well as evaluation through fine-tuning and linear probing methods on smaller datasets serving as downstream tasks. Apparently this approach breaks any local correlations and invariances that modern convolutional neural networks seek to capture, so it is interesting to see that the reported results actually are comparable with some constrastive pretraining methods.
Generative pretraining by sequential pixel prediction
Because the computational cost of self-attention modules increases quadratically with the input sequence length, it is imperative to reduce the image resolutions before reshaping into 1D sequences. The paper experimented with reduced resolutions of \(32^2\times3,48^2\times3,64^2\times3\) on ImageNet, in addition to a new color palette scheme that the authors claim to have reduced sequence length by two thirds without altering color representation. The network itself is identical to the GPT-2 model, with variants in model complexity. Pretraining follows standard practices in training language models; for the auto-regressive objective an upper triangular self-attention mask is added to encode the input ordering, while for the auto-encoding objective the masked pixels are simply replaced with zeros in the input sequence.
The pretrained models are evaluated by linear probing and fine-tuning on a set of smaller downstream datasets, consisting of CIFAR-10, CIFAR-100 and STL-10. Both methods take a global average pooling on the output of the pretrained model, before projecting the features into class logits through a linear projection layer.
Evaluation
The main results reported in the paper are summarized as follows:
- by measure of linear probing, iGPT-L achieved 82.8% accuracy on CIFAR-100, a +2.6% absolute improvement over SimCLR
- by measure of linear probing, iGPT-XL achieved 72% accuracy on ImageNet, inferior by -4.5% absolute points to SimCLR
- by measure of fine-tuning on downstream tasks, iGPT reported comparable or slightly inferior results compared to SimCLR
- by measure of fine-tuning on ImageNet, a 72.6% top-1 accuracy is achieved by largest model iGPT-XL. Although SimCLR only reported top-5 accuracy after fine-tuning in their paper (92.6% when trained with 10% labels), it can be inferred from their reported 76.5% linear probing results on ImageNet that iGPT-XL would be significantly inferior, as full fine-tuning typically would improve the final performance of the network
Overall, the iGPT paper has achieved good results in the sense that the proposed pixel training certainly learned to represent image features to some extend. But the results are not very compelling, especially given the fact that the pretrained models are very huge, with largest model having more than 6.8B parameters (in perspective, state-of-the-art supervised learning model, EfficientNet-B7, has just 66M parameters with 84.4% top-1 accuracy).
Comments
This paper is an interesting attempt at transferring the success of self-supervised learning in NLP domain to the image domain. Its main significance perhaps lies with the fact that such a simple and counter-intuitive objective as the pixel training, could actually produce a model that reaches a level of accuracies on image classification that validates its proposition. On the other hand, while being an original and experimentally thorough investigation, the paper suffers from a main drawback, in that it didn’t actually try to solve an image problem. This led to the result of an unnecessarily large model producing tolerable but otherwise unsatisfying results.
While it is still a debate of whether generative pretraining is the right path forward in self-supervised learning for images, videos, etc., it is evident that any future attempt should start with devising a pretraining objective that aims at learning representations inherent to the input data. For instance, would a jigsaw-like two dimensional AE objective be beneficial? Then there is the challenge of modeling probabilistic distributions over continuous modalities such as images or videos, which would require architectural innovations.
Reference
- Alec Radford et al, “Improving Language Understanding by Generative Pre-Training”, OpenAI 2018
- Alec Radford et al, “Language Models are Unsupervised Multitask Learners”, OpenAI 2019
- Jacob Devlin et al, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”, NAACL-HLT 2019
- Zhilin Yang et al, “XLNet: Generalized Autoregressive Pretraining for Language Understanding”, NeurIPS 2019
- Ashish Vaswani et al, “Attention Is All You Need”, NeurIPS 2017
- Tomas Mikolov et al, “Efficient Estimation of Word Representations in Vector Space”, ICLR 2013
- R. Devon Hjelm et al, “Learning deep representations by mutual information estimation and maximization”, ICLR 2019
- Kaiming He et al, “Momentum Contrast for Unsupervised Visual Representation Learning”, CVPR 2020
- Xiao Liu et al, “Self-supervised Learning: Generative or Contrastive”, Arxiv 2020
- Ting Chen et al, “A Simple Framework for Contrastive Learning of Visual Representations”, ICML 2020