EfficientNet: One Net To Rule Them All?
This blog post briefly introduces the paper “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks” by Mingxing Tan & Quoc V.Le, ICML 2019. In the paper, the authors detailed a paradigm to design convolutional neural networks based on an augmented form of neural architecture search, where the search space is reduced considerably through factorization of the search procedure. A baseline architecture is produced, which is subsequently modified by a compound scaling scheme proposed in the paper to simultaneously scale the model in depths, widths and resolution dimensions in a hollistic manner. The result is a set of networks termed EfficientNets, widely ranging in their complexity, which achieve state-of-the-art or highly competitive results against mainstream benchmark models under comparable resource constraints in classificiation and transfer tasks.
Modern convolutional neural networks typically are developed and benchmarked under a fixed resource budget, commonly in the form of limiting the number of trainable parameters in the network, the number of FLOPs required during inference of a sample, and in scenarios where the responsiveness of the model is critical such as models deployed on mobile platforms, the latency or throughput of inference. It is therefore of considerable practical significance that a model can be designed to accomodate a resource constraint, and preferrably, to be adapted to a different set of constraints by simple scaling schemes without the need of re-design.
To produce models that retain performance competitiveness under a wide range of resource budgets, a baseline architecture needs to be designed first. The paper opted for a NAS-based approach that is built upon a previous work by the same authors on neural architecture search for mobile platforms, termed MnasNet2, where a multi-objective reward that incorporates both accuracy and inference latency on target platform is calculated to train the controller network.
As with any NAS method, composition of the search space is critical to the performance of algorithm. In the MnasNet paper, a search space primarily comprised of mobile-inverted-bottleneck layers3 is used due to their superior performance in building models for mobile platforms. Another factor is the search space size, as NAS methods are notoriously costly to train4. MnasNet first defines a skeleton network architecture comprising of a sequence of blocks. With this skeleton network, each block is associated with its own block-level search space, and only one search is required to produce a block of several layers (number of layers is also a searchable parameter in the search space, along with the type of the layer). By factorizing the search procedure from searching on per-layer level to searching on per-block level, this alteration effectively reduces the overall search space size to produce a final baseline network of the same depth by a factor of \(e^\frac{1}{N}\), where N is the average number of layers per block in the network.
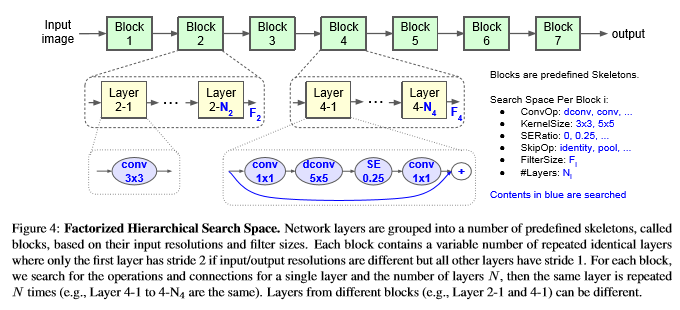
image source: MnasNet paper
It has long been established in the deep learning community that scaling up a model could lead to better performance on a given dataset. While earlier ground-breaking works such as VGG5 and ResNet6 mostly validated the benefits of increasing network depths, recent works have also begun to explore other dimensions for scaling, including model width7 and input resolution. As noted in the paper, most of the previous works on network scaling has focused on scaling exactly one of the possible dimensions at a time. However, the authors observe that scaling up any single dimension of network depth, width or input resolution improves accuracy only with diminishing gains. This is further complicated by the observations that the effects of scaling up any single dimension are interdependent on other dimensions. The preliminary study results indicate that it might be beneficiary to scale up more than one dimensions simultaneously.
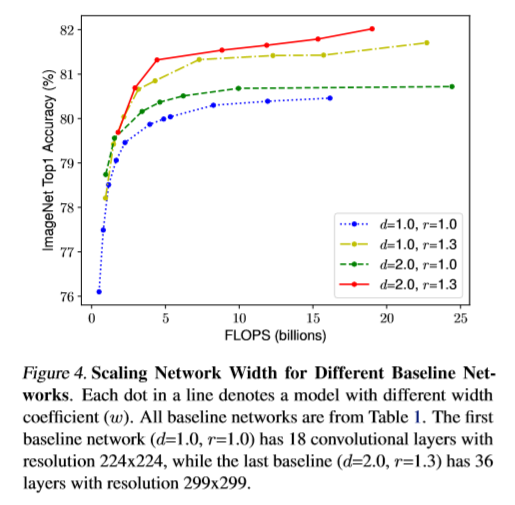
image source: EfficientNet paper
EfficientNet uses the same factorized hierarchical search space and produces a baseline network very similar to MnasNet. The main difference between the two search procedures is that, instead of incorporating actual inference latency measured on a test platform into the reward signal as done in the MnasNet paper, EfficientNet targets the traditional FLOPs metric. Thus the resulting baseline, termed EfficientNet-B0, is more platform-agnostic. The baseline network subsequently undergoes a compound scaling scheme that scales in all three dimensions (depth, width, resolution) hollistically.
Compound Scaling
The scaling scheme proposed in EfficientNet uses a single hyperparameter termed compound scaling factor to scale the network’s depth, width and resolution simultaneously, according to the following formula:
\[\begin{split} d&=\alpha^\phi\\ w&=\beta^\phi\\ r&=\gamma^\phi \end{split}\]where d, w, r stands for the scaling factors for depth, width and resolution, respectively. The compound scaling factor \(\theta\) is chosen as a user-specified hyperparameter for the model produced. The constants \(\alpha, \beta, \gamma\) are empirically selected through a grid search on a small baseline network that seeks to maximize the performance of the resulting scaled network. The search is constrained by \(\alpha*\beta^2*\gamma^2\approx2\), which hypothesizes that when \(\theta=1\) the network should have approximatedly twice the complexity in terms of FLOPs. The authors noted that the search cost quickly becomes prohibitively expensive with the size of the model.
The resulting models are termed EfficientNets-B0~B7 with increasing network complexity, by setting different values for \(\theta\) and scales the baseline EfficientNet-B0 network accordingly. The networks primarily consist of mobile-inverted-bottleneck layers with kernel sizes of 3x3 and 5x5. The paper follws that of MobileNet-V23 in using ReLU6 as the activation function and adds the squeeze-and-excitation optimization layers following the SENet8. The largest model, EfficientNet-B7, has 66M parameters and 37B FLOPs in inference, while the smallest model, EfficientNet-B0, is a network with 5.5M parameters and consumes 0.39B FLOPs. Or in other words, the EfficientNet paradigm could produce models with a dynamic range in complexity of up to 12x as measured by number of parameters or up to 95x as measured by inference cost. There is no apparent limitations inherent to the design paradigm to further increase or decrease the model complexity to accomodate various resource budgets.
Evaluation
The EfficientNets are first evaluated on ImageNet classification task. The results are shown in Fig.5 which plots ImageNet top-1 accuracy vs FLOPs of each model. Similar trend is also reported in Fig.1 of the paper, which plots top-1 accuracy vs number of parameters. It is apparent that the compound scaling method used with EfficientNet baseline could monotonically improve its accuracy, abeit still suffers from saturating at around ~84% top-1 accuracy, which is nonetheless the state of the art result. Notably, EfficientNet models not only achieved higher accuracy against benchmark models with comparable computation complexity, it does so against models of various architectures and across a wide dynamic range. Considering the fact that the EfficientNet variants are generated by a principled and largely automated design paradigm, it is therefore not only the actual models but also the design paradigm that has been shown to be superior.
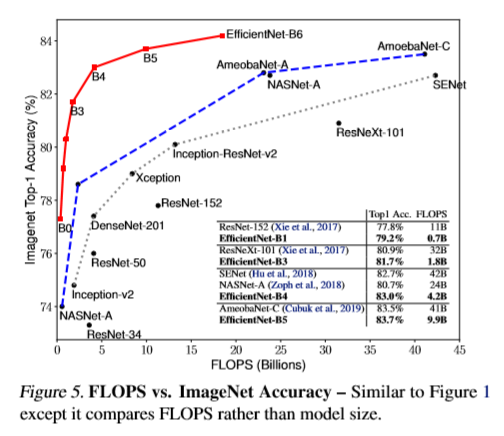
image source: EfficientNet paper
The authors next evaluates EfficientNets on transfer tasks. They follow common practice in transfer learning by fine-tuning pretrained model checkpoints with ImageNet on the specific transfer datasets. The transfer tasks include several widely used datasets such as CIFAR-10/100. The accuracy results are plotted against number of trainable parameters in the models. Note that although the scaling does not necessarily produce monotonical accuracy improvements, the overall trend still strongly supports that scaling up a model hollistically can lead to robust performance gains.
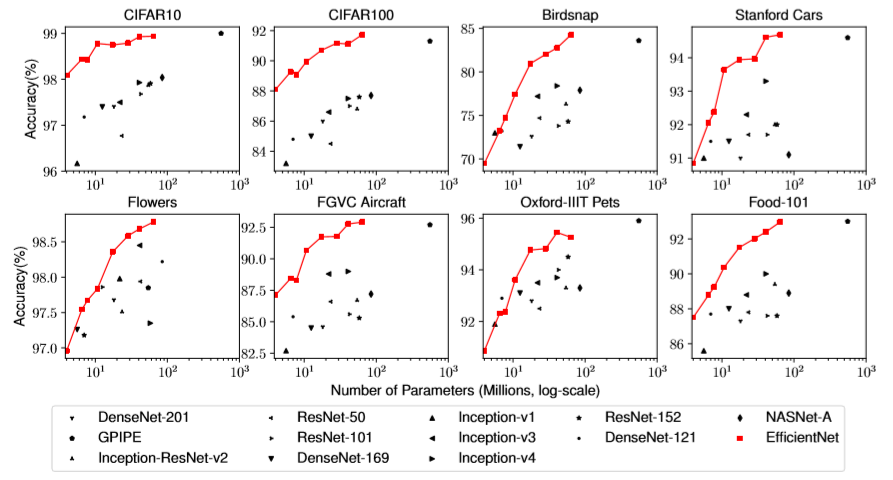
image source: EfficientNet paper
Comments
The evaluation results reported in the paper provides strong evidence for the superiority of the EfficientNet design paradigm, which is a largely automated, three-step approach to design a range of convolutional networks of varying complexity:
- Step 1: generate a baseline architecture through neural architecture search. Although the paper emphasizes the contribution of the hollistic scaling approach, it is evident that the baseline architecture is already a high-performing, efficient network. To produce such a baseline, the paper opted for a particular form of NAS which fixes the skeleton of the baseline architecture as a sequence blocks with pre-defined search spaces. The critical difference between the NAS method used in this context and a general NAS-like algorithm is that, finding the best network in terms of the metrics set for the architecture search might no longer be the sole objective. Indeed, it is fair to hypothesize that a network which performs optimally under a given set of search metrics might not necessarily be the most suitable baseline subsequently for scaling. It is possible to imagine searching a network architecture that is very small in sizes and performs perhaps only mediocrely on the dataset, but can be scaled up effectively with high returns. The benefit would then be a considerable reduction in architectural search costs. However, challenges are also raised in terms of what characteristics must a network possess to be a good baseline? It would be interesting to see if any future works explore these questions.
- Step 2: do a grid search to find values for the scaling constants. The paper noted that this process can be prohibitively costly if the search grid is performed on a large enough baseline model. I wonder if this step could be incorporated into a modified version of step 1, where we search not only a small baseline network but also the scaling constants. The network is then evaluated by measuring accuracies of a certain number of its scaled up versions on the test set. A compound reward signal may take the form as, for instance, weighted averages of the test set accuracies to be fed to the controller during training. The increase of search cost for evaluating more child networks might then be partially offset by reducing the size of the child network being searched.
- Step 3: fix the scaling constants for each dimensions and hollistically scales up the baseline model using a compound scaling factor. Currently the scaling scheme applies to the entire network, in the future it might be interesting to see if scaling with finer grains (e.g., layer-wise or block-wise) would be more beneficiary.
Reference
- Mingxing Tan & Quoc V.Le, “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks”, ICML 2019
- Mingxing Tan et al, “MnasNet: Platform-Aware Neural Architecture Search for Mobile”, CVPR 2019
- Mark Sandler et al, “MobileNetV2: Inverted Residuals and Linear Bottlenecks”, CVPR 2018
- Barret Zoph & Quoc V.Le, “Neural Architecture Search with Reinforcement Learning”, ICLR 2017
- Karen Simonyan & Andrew Zisserman, “Very Deep Convolutional Networks for Large Scale Image Recognition”, ICLR 2015
- Kaiming He et al, “Deep Residual Learning for Image Recognition”, CVPR 2016
- Andrew G. Howard et al, “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications”, CoRR 2017
- Jie Hu et al, “Squeeze-and-Excitation Networks”, CVPR 2018