Zoo of Deep Learning Modules
Modules are the building blocks of deep learning. This post introduces some of the most widely used differentiable modules in modern networks, from the basic parameter-free operations such as pooling, activations, to linear, attention and the more complex reccurent modules. For each module introduced, either a set of mathematical formulations or a PyTorch/Numpy implementation of the module’s forward, backward, and when applicable, parameter gradient methods is provided. Regular updates will be made to include some of the more recent progresses in literature pertaining to the design, analysis or integration of novel modules.
Deep learning is a heavily loaded term. Sometimes it is used to refer to concepts more suitably described by terms such as deep neural networks, supervised learning, representation learning, etc. Yan LeCun gave a generalized definition of deep learning at a keynote event in AAAI 2020 as follows:
“Deep learning is building a system by assembling parameterized modules into a (possibly dynamic) computation graph, and training it to perform a task by optimizing the parameters using a gradient-based method.”
This blog post will provide a glossary of the modules, which are essentially the building blocks of modern deep learning systems. Note that only differentiable modules would be included here, as they could be trained by gradient-based methods in a network.
Any differentiable module is expected to perform three sets of computations:
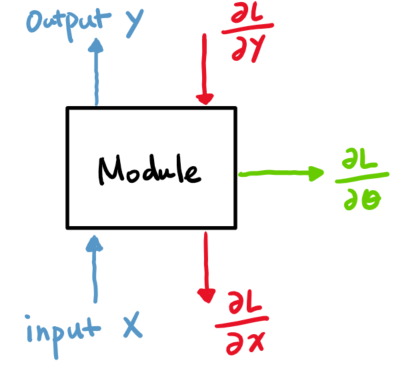
- forward propagation (fprop), which starts from the input and propagates the mappings through the graph to produce an output and a loss; this is the process that defines the network’s functional mapping and is used in inference stage
- backward propagation (backprop), which starts from the loss and propagates its gradients w.r.t. the intermediate states backwards through the graph to the input; this is the process that is used in training stage to produce gradients
- parameter gradient, which moves through the graph along with the back propagation to produce gradients of the loss w.r.t. network parameters; these gradients are subsequently used in any gradient-based optimization methods (e.g., SGD) to update the network parameters
Karen Osidero’s lecture at UCL provided a good reference as to why these three methods are needed to define a module.
In simple terms, modern frameworks such as TensorFlow or PyTorch are based on automatic differentiation, which works by tracking the gradients’ propagation through the network as a stack of well-defined, differentiable modules. A designer need not worry about the cumbersome details of gradient calculations, but are only tasked with specifying the modules and their input-output relationships. In general, one could devise any form of modules and incorporate these modules into a network architecture with ease, so long as the modules are differentiable and are defined with the aforementioned three methods.
Below are some widely used modules:
Notation:
- \(x\): scalar
- \(\vec{x}\): vectors
- \(x_i\): scalar element of vector \(\vec{x}\)
- \(X\): matrix
- vectors adopt column format; partial derivatives adopt the numerator layout
Parameter-free modules
Functional layers such as element-wise operations, activations, loss functions, etc., although parameter-free, are still most often implemented following the same modular definition. This facilitates the insertion of the functional layers into a network definition with ease.
| Type | Module | Forward-pass | Backward-pass |
|---|---|---|---|
| Element-wise | Add | \(\vec{y} = \vec{a} \oplus \vec{b}\) | \(\frac{\partial{L}}{\partial{\vec{a}}} = \frac{\partial{L}}{\partial\vec{y}}\) |
| Multiply | \(\vec{y}=\vec{a}\odot\vec{b}\) | \(\frac{\partial{L}}{\partial{\vec{a}}}=\frac{\partial{L}}{\partial{\vec{y}}}\odot\vec{b}\) | |
| Group | Sum | \(y=\sum x_i\) | \(\frac{\partial{L}}{\partial{\vec{x}}}=\frac{\partial{L}}{\partial{y}}\vec{1}^T\) |
| Max | \(y=max\{x_i\}\) | \(\frac{\partial{L}}{\partial{x_i}}=\begin{cases}\frac{\partial{L}}{\partial{y}}&\;\;\text{if }i\text{ was maximal}\\0&\;\;\text{if otherwise}\end{cases}\) | |
| Switch | \(\vec{y}=\vec{s}\odot\vec{x}\) | \(\frac{\partial{L}}{\partial{\vec{x}}}=\frac{\partial{L}}{\partial{\vec{y}}}\odot\vec{s}^T\) | |
| Activation | Relu1 | \(y_i=max\{0,x_i\}\) | \(\frac{\partial{L}}{\partial{x_i}}=\begin{cases}\frac{\partial{L}}{\partial{y_i}}&\hspace{42pt}\text{if }x_i>0\\0&\hspace{42pt}\text{if otherwise}\end{cases}\) |
| Leaky Relu2 | \(y_i=max\{0.01x_i,x_i\}\) | \(\frac{\partial{L}}{\partial{x_i}}=\begin{cases}\frac{\partial{L}}{\partial{y_i}}&\hspace{24pt}\text{if }x_i>0\\0.01\frac{\partial{L}}{\partial{y_i}}&\hspace{24pt}\text{if otherwise}\end{cases}\) | |
| Elu3 | \(y_i=\begin{cases}x_i&\;\;\text{if }x_i>0\\\alpha(e^{x_i}-1)&\;\;\text{if otherwise}\end{cases}\) | \(\frac{\partial{L}}{\partial{x_i}}=\begin{cases}\frac{\partial{L}}{\partial{y_i}}&\hspace{7pt}\text{if }x_i>0\\\frac{\partial{L}}{\partial{y_i}}(y_i+\alpha)&\hspace{7pt}\text{if otherwise}\end{cases}\) | |
| Selu4 | \(y_i=\begin{cases}\lambda x_i&\text{if }x_i>0\\\lambda\alpha(e^{x_i}-1)&\text{if otherwise}\end{cases}\) | \(\frac{\partial{L}}{\partial{x_i}}=\begin{cases}\frac{\partial{L}}{\partial{y_i}}\lambda&\hspace{1pt}\text{if }x_i>0\\\frac{\partial{L}}{\partial{y_i}}(y_i+\lambda\alpha)&\hspace{1pt}\text{if otherwise}\end{cases}\) | |
| Sigmoid | \(y_i=\frac{1}{1+e^{-x_i}}\) | \(\frac{\partial{L}}{\partial{\vec{x}}}=\frac{\partial{L}}{\partial{\vec{y}}}diag(\vec{y}(\vec{1}-\vec{y})^T)\) | |
| Softmax | \(y_i=\frac{e^{x_i}}{\sum\limits_{\forall k}e^{x_k}}\) | \(\frac{\partial{L}}{\partial{\vec{x}}}=\vec{s}^T-\vec{y}^T\sum\limits_{\forall{i}}s_i\\\text{ where }s_i=\frac{\partial{L}}{\partial{y_i}}y_i\) | |
| Softplus1 | \(y_i=\log(e^{x_i}+1)\) | \(\frac{\partial{L}}{\partial{\vec{x}}}=\frac{\partial{L}}{\partial{\vec{y}}}diag(\frac{e^{x_i}}{e^{x_i}+1})\) | |
| Tanh | \(y_i=\frac{e^{x_i}-e^{-x_i}}{e^{x_i}+e^{-x_i}}\) | \(\frac{\partial{L}}{\partial{\vec{x}}}=\frac{\partial{L}}{\partial{\vec{y}}}diag(I-\vec{y}\vec{y}^T)\) | |
| Loss | Cross-Entropy | \(L=-\sum\limits_{\forall{i}}p_i\log{x_i}\) | \(\frac{\partial{L}}{\partial{x_i}}=-\frac{p_i}{x_i}\) |
| Squared Error | \(L=\lVert{\vec{t}-\vec{x}}\rVert^2=\sum\limits_{\forall{i}}(t_i-x_i)^2\) | \(\frac{\partial{L}}{\partial{\vec{x}}}=-2(\vec{t}-\vec{x})^T\) | |
| Pooling | MaxPooling2D | \(\begin{split}y_{i,j}&=max(x_{Ui:Ui+p,Uj:Uj+q})\\\text{U: }&\text{stride}\\\end{split}\) | \(\DeclareMathOperator*{\argmax}{argmax}\frac{\partial{L}}{\partial{x_{i,j}}}=\begin{cases}\sum\limits_{i'}^H\sum\limits_{j'}^H\frac{\partial{L}}{\partial{y_{i',j'}}}&\hspace{10pt}\text{if }\argmax\limits_{i',j'}\{x_{Ui':Ui'+p,Uj':Uj'+p}\}=i,j\\0&\hspace{10pt}\text{otherwise}\end{cases}\) |
| AveragePooling2D | \(y_{i,j}=\frac{1}{pq}\sum\limits_p^P\sum\limits_q^Qx_{Ui+p,Uj+q}\) | \(\frac{\partial{L}}{\partial{x_{i,j}}}=\frac{1}{pq}\sum\limits_{\frac{i-p}{U}}^P\sum\limits_{\frac{j-q}{U}}^Q\frac{\partial{L}}{\partial{y_{\frac{i-p}{U},\frac{j-q}{U}}}}\) | |
| Regularization | Drop-out7 | \(\vec{y}=\frac{1}{1-q}\vec{D}\odot\vec{x}\\\text{where }\vec{D}\text{ is the drop-out swith vector}\) | \(\frac{\partial{L}}{\partial{\vec{x}}}=\frac{1}{1-q}\frac{\partial{L}}{\partial{\vec{y}}}\odot\vec{D}^T\) |
Linear modules
Linear layers are used to perform affine transformations. Usually they are the layers with the majority of learnable parameters in a network, thus serving as the cornerstones. Commonly used linear layers include fully-connected layers and convolutional layers.
FC
Fully connected layer (FC for short) can be traced back to the early days of artificial neural networks, where they are used to construct the multi-layer perceptron8 model. For a considerable period of time (1960’s - early 2000’s) the fully connected layers are the only major building blocks for neural networks. In modern models, however, FC layers are no longer used throughout the network, as they consume too much computation budgets for the data-intensive training today. Instead, FC layers typically function as:
- the projection or embedding layers in neural language models using pretrained word embeddings
- a last-level projection layer to project the features into class logits in convolutional networks
- some network-in-network setting, e.g., used to for the squeeze and excitation operations in networks with SE optimizations10
Below is the modular formulation of an FC layer. Note that parameter-pass involves a vector-by-matrix derivative, which could be represented compactly by the kronecker product with an identity matrix. In practice this simply reduces to a vector multiplication by input vector \(x\) and producing a matrix.
- forward-pass
- backward-pass
- parameter-pass
Conv-2D
Convolutional layers could be viewed as a FC layer with weight sharing to reduce computation9. As convolutional layers are most commonly used to process two-dimensional image data, conv-2d is first introduced, followed by the extensions to 1d (e.g., sequential text data) and 3d (video data) cases.
Convolutional layers have been firmly established as the cornerstones to modern computer vision networks. Dan C.Ciresan et al10 first reported the use of GPU implementation to train a network built with convolutional filters and max-pooling layers. AlexNet11 was the work that propelled convolutional neural networks into the state-of-the-art model for image classificiation, and later many other computer vision tasks, by winning the ILSVRC 2012 challenge with a 57.2% top-5 accuracy. This work has popularized several key enabling techniques, including ReLU, dropout, grouped convolution, and distributed GPU training, as well as raising awareness to the important topics of normalization and initialization in modern networks.
After AlexNet, the design of convolutional networks (for feature extraction, or the ‘back-bone’ network as commonly referred to in recent literature) could be roughly divided into three development stages, as categorized by the driving factors for the performance gains and as signified by two seminar works, the ResNet12 in 2015 and NAS13 in 2017:
- unit-level design: before ResNet, research had been focused on the the building blocks of a convolutional neural network. Major works include the Inception family, which popularized the use of factorized 3x3/1x1 convolutional filters14 and batch normalization15 layers. Although Xception16 came after ResNet and used skip connection, its primary contribution was that it pushed the factorization into extreme by stacking a network with purely depthwise separable filters. These works went beyond the simple yet powerful idea of increasing network depth17 to gain performance, instead they attempted to make the convolutional modules more expressive or computationally more efficient.
- block-level design: while the Inception papers already started to use complex cells with multiple parallel data paths as the building block, the ResNet-like multi-layer bottleneck block became the standard choice in recent state-of-the-art networks. Along with its influential skip connection, which is now a standard way to design convolutional network, ResNet had also popularized the use of bottleneck block, consisting of a 1x1-conv / 3x3-conv / 1x1-conv stack, to reduce computation complexity by forcing a channel-wise bottleneck before the expensive 3x3 convolutional filters12. This design pattern has been favored by several major works later, partly due to its flexibility, as a network became increasing aware of its resource budget. ResNet variants such as ResNeXt18 and WideResNet19 are all modifications or extensions based on the bottleneck block. MobileNet-V120 further reduced computation by using a 3x3 depthwise filter. Its successor, MobileNet-V221, proposed an inverted and linearized version of the bottleneck block, where the expansion factor is greater than 1 and the last-layer activation is removed. The ShuffleNets22, 23 extended the concept of grouped filtering firstly into the pointwise kernels by introducing a channel shuffling operation, and later direclty into the block-level processing by introducing a channel splitting operation. Other notable block-level innovations include DenseNet24, where the idea of skip connection is extended from connecting consecutive layers to connecting all pairs of layers in a dense block.
- network-level design: researchers have always agreed that scaling up a network could most likely improve its performance, albeit with diminishing gains. What they have not agreed on is how to best scale a network. There are too many hyperparameters to be tuned, including but not limited to total number of layers, number of layers for each stack, etc. Earlier works mostly followed a paradigm established by AlexNet and VGG17, where the construction of the network (along with design of its building blocks) is coupled with the scaling of the baseline architecture. Both process were done mannually and heuristically. As the block-level innovations slowly stagnitized, a more effective and hollistic approach to design and scale a network is needed to push performance further. NAS13 provided a solution. Instead of constructing a network mannually from scratch, a neural architecture search is performed over a pre-defined search space comprising of unit-level and/or block-level cells as the building bricks to automatically construct a network layer-by-layer or block-by-block. It is natural to combine a well-trained NAS controller with a well-defined search space to produce a highly competitive baseline architecture. Followed by either automatic or mannual scaling schemes, such a baseline could then be scaled up/down to suit various resource budgets while maintaining its competitiveness. Adopting this design paradigm, works such as MnasNet25 and its successor the EfficientNets26 have produced state-of-the-art convolutional networks across a wide of range of complexities.
Although the network designs have progressed significantly, the most basic convolutional operation remains the same. In modern frameworks such as PyTorch, aside from the kernel sizes and channels, a convolutonal module could be customized by specifying additional parameters, including:
- stride: controls the striding of the convolutional operation over a feature map
- padding: specifies the additional pixels padded on the edges of the feature map before convolving
- dilation: dilated convolution increases the receptive field of the filter without increasing the kernel size
- groups: grouped convolution could reduce computational complexity; an extreme situation is groups=channels, in which case it became depthwise
In modern network design, to alleviate the burden of dimension mismatch between skip connections, it is desirable to customize the convolutional modules such that they preserve feature map dimensions exactly when stride is 1. For an input feature map of size \([H_{in}, W_{in}]\), a conv-2d filter would produce an output feature map of the size:
\[\begin{split} H_{out} &= \frac{H_{in}+2*padding[0]-dilation[0]*(kernel\_size[0]-1)-1}{stride[0]}+1\\ W_{out} &= \frac{W_{in}+2*padding[1]-dilation[1]*(kernel\_size[1]-1)-1}{stride[1]}+1 \end{split}\]For instance, if the kernel size is 5, then setting the padding=2 and dilation=1 would ensure the preservation of dimensions. Such a configuration would also exactly halve the feature maps if stride=2, another desirable property, as setting stride=2 is the most common downsampling technique employed in modern networks.
Another interesting anecdote about convolutional filters is that they are actually not convolutional at all. The proper name for the actual operation that they do perform should in fact be auto-correlation, borrowed from the field of statistics. The difference is very subtle: auto-correlation became the true convolution if the input feature maps are transposed first, which of course is not necessary. Nonetheless, the name “convolution”, just as its status as the corner-stone of modern computer vision networks, have stood the test of time.
The sections below would now introduce the basic operations of a 2D convolutional filter, followed by 1D, 3D and separable convolutional filters.
- forward-pass
- backward-pass
- parameter-pass
Conv-1D
- forward-pass
- backward-pass
- parameter-pass
Conv-3D
- forward-pass
- backward-pass
- parameter-pass
SeparableConv-2D
Separable convolutions break a standard convolution into two steps: a depthwise convolution focusing on each channel individually, followed by a point-wise operation across the channels. Note that while the following mathematical expressions treated the separable convolution as a single module, in practice it is common to implement this operation as a stack of two seperate layers, for instance in PyTorch:
def forward(self, x):
""" forward method without dropout """
x = self.relu(self.bn1(self.convdw1(x))) # convdw1: a depthwise layer by setting groups = inplanes = outplanes
x = self.relu(self.bn2(self.conv2(x))) # conv2: a 1x1 pointwise layer
return x
- forward-pass
- backward-pass
- parameter-pass
Normalization
Batch Normalization (BN)15 is the standard practice for convolutional networks, employed by most if not all of the major models. It works by approximately normalizing the activations of a layer into a normal distribution with zero mean and unit variance for each of its channels. The original concept of reducing covariate shift had not yet been fully understood or accepted as the reason for why BN works so well. Batch Normalization technique is tightly related to the practice of mini-batching, a standard method that feeds the network with batches of data samples and trains with stochastic gradient descent on the entirety of the batch. It uses the mini-batch statistics as estimates to the true means and variances of the distributions of activations. Two learnable scaling and shifting factors control the module’s final behavior and are trained along with the network parameters.
The coupling with mini-batch setting provided BN with computationally efficient estimation for the distributions, but it also limited its application to other settings, for instance when the batch size is too small or when the model is trained fully stochastically. Particularly for sequence models, including RNN’s and Transformerscite, Layer Normalization (LN)27 is a more popular choice. LN works in the same way as BN, except that it now estimates the true mean and variance of distributions through per-layer statistics (the activations) instead of per-minibatch. The most significant application for LN is perhaps the multi-head self-attention modulescite, the counterpart of convolution filters in modern Transformer networks.
The vanilla Layer Normalization combines the activations from all channels in that layer. This makes it an undesirable choice for convolutional networks, as it essentially altered the network’s expressiveness by providing additional cross-channel information to its layers. Furthermore, generally the feature maps are gradually downsampled through the network; the shallow layers have large activation maps and thus expensive Layer Norm computations, while the deeper layers have very small activation maps to produce any meaningful estimation statistically. To bridge the gap between LN and BN, several subsequent works have been proposed. Instance Normalization (IN)28 and Group Normalization (GN)29 are also based on the same idea of normalizing a layer’s activations by estimating the true mean and variance of the distribution, but they differ in how the estimations are produced: IN uses per-channel statistics, thus removing the cross-channel information in LN; GN seeks the middle ground between IN and LN by using statistics from a group of multiple channels. Another notable but less commonly used method is Weight Normalization (WN)30, which works by normalizing the layer weights instead of the layer activations (computationally cheaper, as there are usually much more activations than weights for a given layer).
Since most of the commonly used normalization methods are variants of Batch Normalization, here its modular formulation is included, following the definitions used in the original paper by Sergey Ioffe and Christian Szegedy.
BN
- forward-pass
- backward-pass
- parameter-pass
Reccurent modules
SimpleRNN
- forward-pass
- backward-pass
- parameter-pass
LSTM
- forward-pass
- backward-pass
- parameter-pass
GRU
- forward-pass
- backward-pass
- parameter-pass
Attention
Attention mechanism has been at the core of state-of-the-art language models such as GPT36, BERT37, XLNet38 etc.. These models are variants of the Transformer39 architecture, which consists of as building blocks a particular type of attention mechanisms known as self-attention.
Modern attention mechanism is first proposed by Bahdanau et al35 in the context of language modeling. In general, an attention module operates on a tuple of three input tensors: query \(Q\), key \(K\) and value \(V\).
Since then, various types of attention modules have been developed.
Multi-Head Self-Attention
Bibliography
- Ian Goodfellow, Yoshua Bengio, Aaron Courvill, “Deep Learning”
Online Materials
- Simon Osindero, “Lecture-03: Neural Network Foundations”, the DeepMindxUCL lectures 2018
- Jefkine, “Backpropagation In Convolutional Neural Networks”
- Christopher Olah, “Understanding LSTM networks”
- Van Huyen DO, “Back propagation in Long Short Term Memory (LSTM)”
References
- Xavier Glorot et al, “Deep Sparse Rectifier Neural Networks”, AISTATS 2011
- Andrew L. Maas et al, “Rectifier Nonlinearities Improve Neural Network Acoustic Models”, ICML 2013
- Djork-Arn´e Clevert et al, “Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs)”, ICLR 2016
- Günter Klambauer et al, “Self-Normalizing Neural Networks”, NeurIPS 2017
- Dan Hendrycks et al, “Gaussian Error Linear Units (GELUs)”, Arxiv 2018
- Kaiming He et al, “Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification”, ICCV 2015
- Nitish Srivastava et al, “Dropout: A Simple Way to Prevent Neural Networks from Overfitting”, JMLR 2014
- Frank Rosenblatt, “The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain”, 1958
- Yan LeCun et al, “Backpropagation Applied to Handwritten Zip Code Recognition”, Neural Computation 1989
- Dan C.Ciresan et al, “Flexible, High Performance Convolutional Neural Networks for Image Classification”, IJCAI 2011
- Alex Krizhevsky et al, “ImageNet Classification with Deep Convolutional Neural Networks”, NeurIPS 2012
- Kaiming He et al, “Deep Residual Learning for Image Recognition”, CVPR 2016
- Barret Zoph & Quoc V.Le, “Neural Architecture Search with Reinforcement Learning”, ICLR 2017
- Christian Szegedy et al, “Rethinking the Inception Architecture for Computer Vision”, CVPR 2016
- Sergey Ioffe & Christian Szegedy, “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift”, ICML 2015
- Francois Chollet, “Xception: Deep Learning with Depthwise Separable Convolutions”, CVPR 2017
- Karen Simonyan & Andrew Zisserman, “Very Deep Convolutional Networks for Large-Scale Image Recognition”, ICLR 2015
- Saining Xie et al, “Aggregated Residual Transformations for Deep Neural Networks”, CVPR 2017
- Sergey Zagoruyko & Nikos Komodakis, “Wide Residual Networks”, Arxiv 2016
- Andrew G.Howard et al, “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications”, CoRR 2017
- Mark Sandler et al, “MobileNetV2: Inverted Residuals and Linear Bottlenecks”, CVPR 2018
- Xiangyu Zhang et al, “ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices”, CVPR 2018
- Ningning Ma et al, “ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design”, EECV 2018
- Gao Huang et al, “Densely Connected Convolutional Networks”, CVPR 2017
- Mingxing Tan et al, “MnasNet: Platform-Aware Neural Architecture Search for Mobile”, CVPR 2019
- Mingxing Tan & Quoc V.Le, “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks”, ICML 2019
- Jimmy Lei Ba et al, “Layer Normalization”, Arxiv 2016
- Dmitry Ulyanov et al, “Instance Normalization: The Missing Ingredient for Fast Stylization”, Arxiv 2017
- Yuxin Wu & Kaiming He, “Group Normalization”, EECV 2018
- Tim Salimans et al, “Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks”, NeurIPS 2016
- Alec Radford et al, “Language Models are Unsupervised Multitask Learners”, OpenAI 2019
- Jacob Devlin et al, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”, NAACL-HLT 2019
- Zhilin Yang et al, “XLNet: Generalized Autoregressive Pretraining for Language Understanding”, NeurIPS 2019